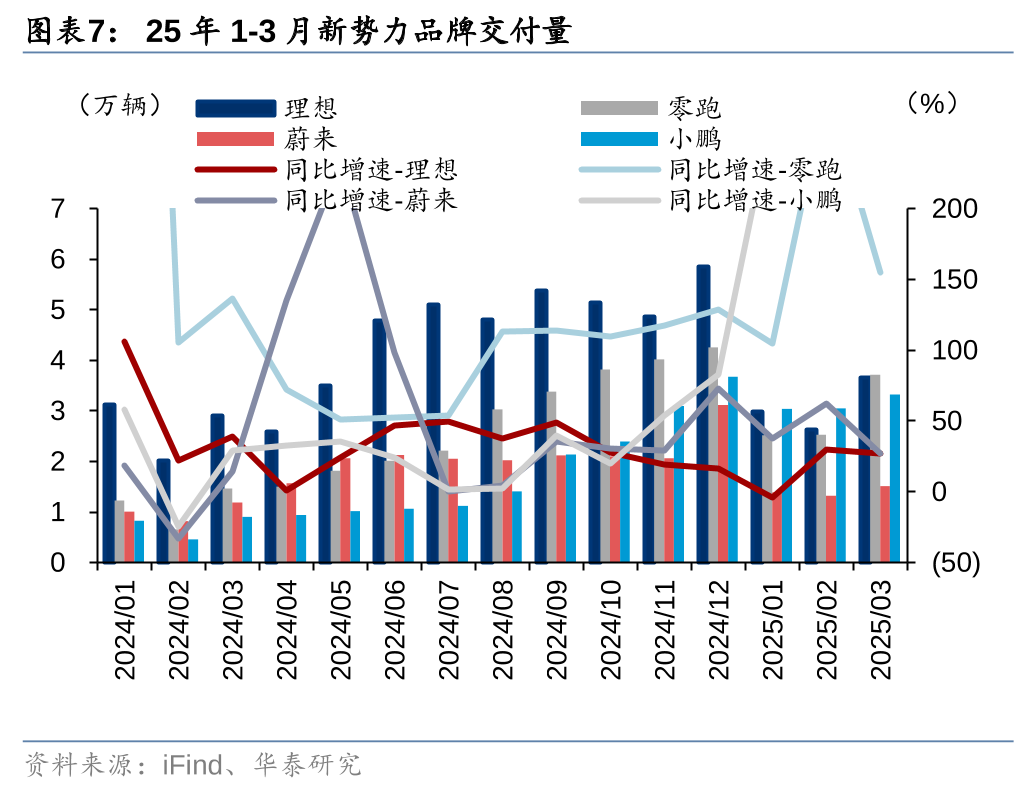
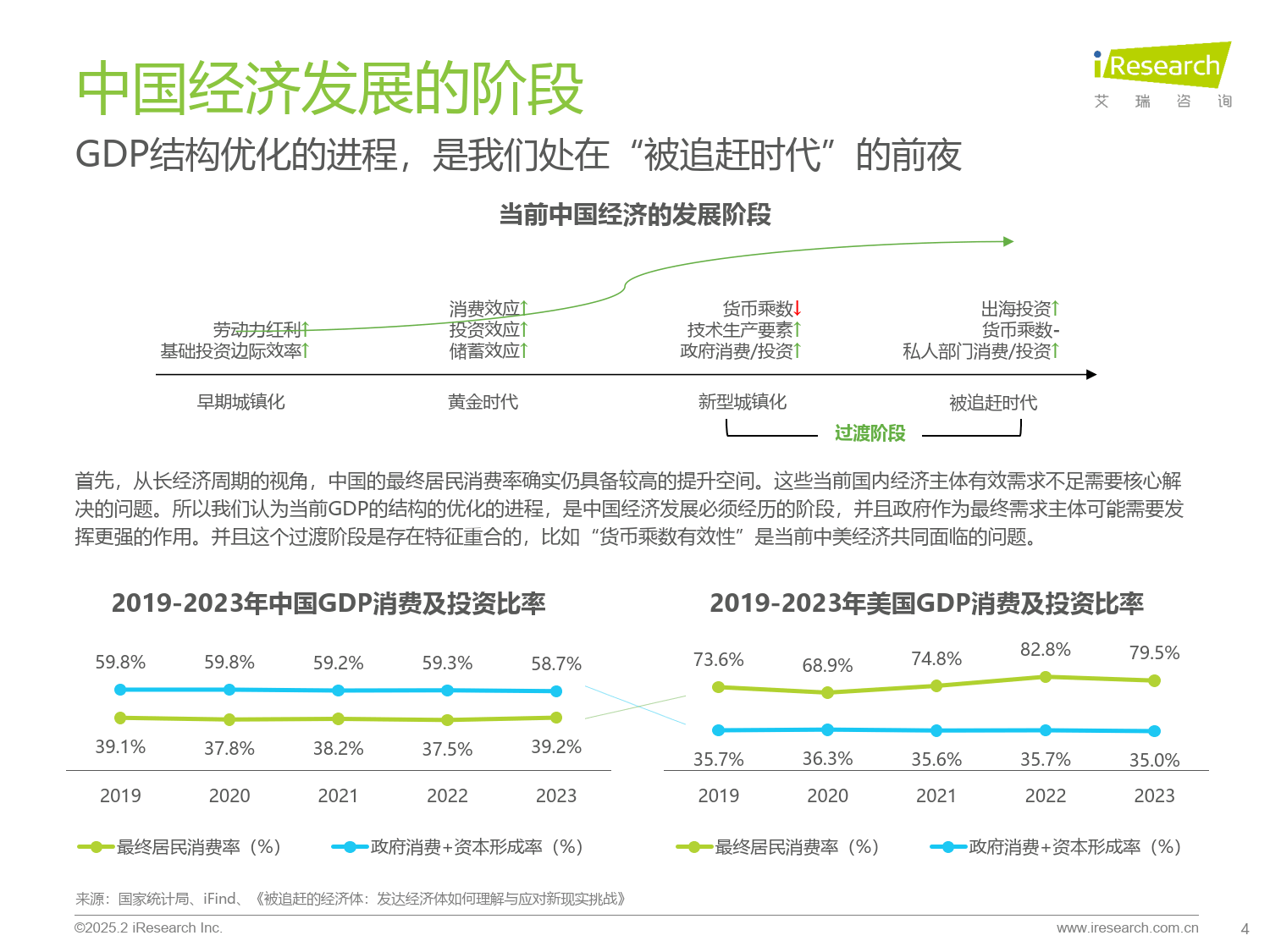
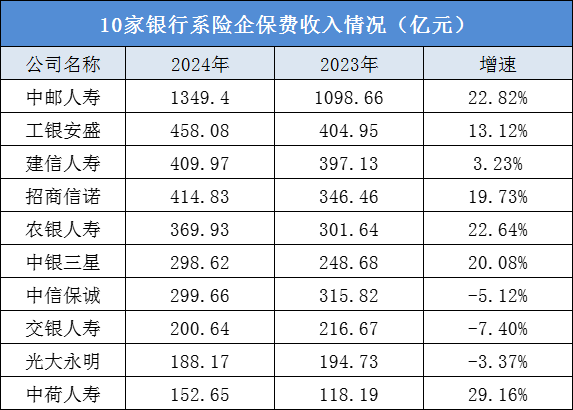
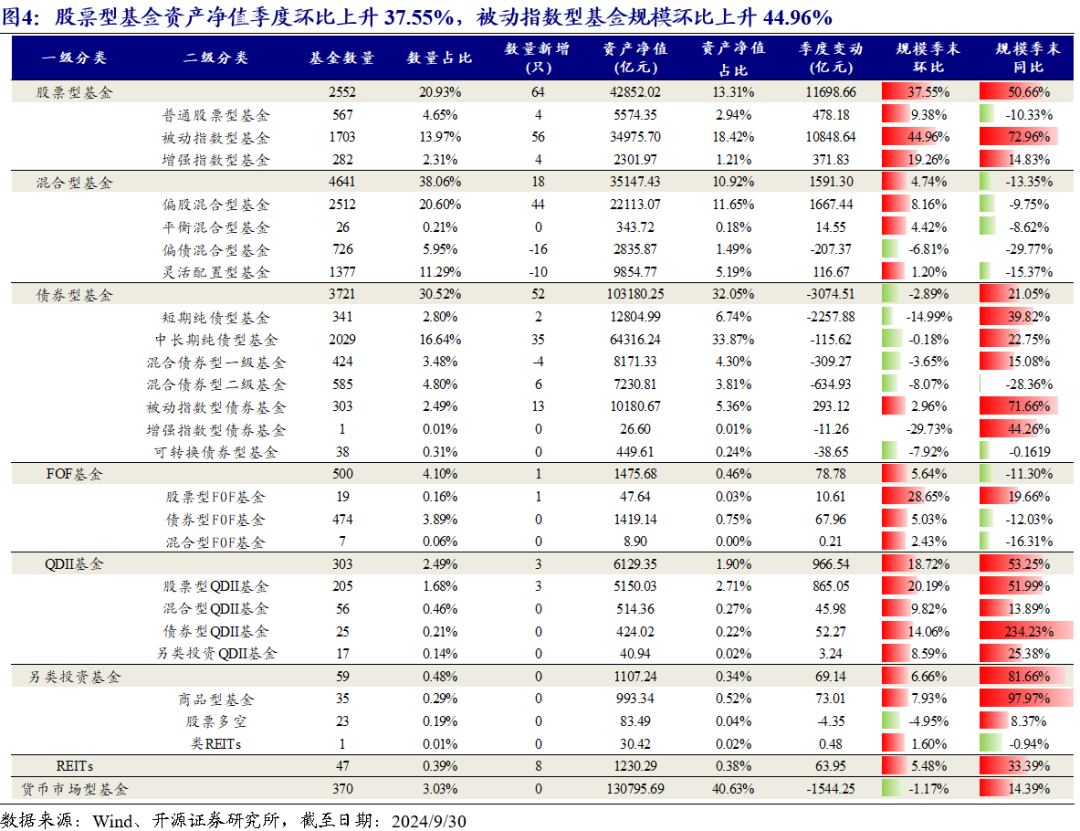
一直以来,广发证券主动担起金融机构的主体责任,发挥业务优势,打造丰富的投教载体,贯彻资本市场人民性立场,树牢金融为民的理念,引领投资者教育工作走在行业前列。随着一系列新政策的出台,我国资本市场进入新发展阶段,广发证券特在中国证券报开设“投研财富+”投教专栏,聚焦新质生产力方向和市场热点,向广大投资者普及专业投研框架、分享专业机构观点,帮助投资者掌握投资分析方法,更加有效维护投资者特别是中小投资者合法权益,持续提升投资者的获得感,聚力推动我国资本市场实现高质量发展。

最近,谷歌新一代大模型Gemini 3 Pro在复杂推理和跨模态理解上取得突破,展现出令人惊叹的通用智能潜力。与此同时,国内DeepSeek等开源大模型社区也异常活跃,不断推出参数规模更大、性能更强、应用场景更丰富的模型版本。这些进展标志着全球人工智能发展正进入一个新的爆发期,而驱动这场变革的核心引擎,正是日益强大的计算能力——算力。在这一浪潮中,中国凭借完整的产业链布局、快速的技术迭代和不断增强的产业协同能力,正在全球算力生态中构建起一条日趋完备、富有韧性的“中国算力链”,成为AI时代不可或缺的动力源。

从大模型爆发看算力需求的革命性变化

大模型,特别是万亿参数级别的模型训练,对算力提出了前所未有的需求。一次完整的GPT-4级别模型训练,需要消耗上万张高性能AI加速卡连续运转数月,电力消耗相当于一个小型城市数年的用电量。这不仅是芯片算力的比拼,更是对整个计算系统——从芯片架构、高速互联、存储带宽到散热能效的全方位考验。
中国算力产业链正是在这种极端需求下,加速了技术演进和产业升级。从最初主要依赖进口设备搭建算力中心,到现在逐步形成从底层芯片、关键部件到整机系统、软件生态的完整产业能力,中国算力链正在经历从“跟随”到“并跑”甚至在某些领域“领跑”的深刻转变。
算力基础设施:光模块与PCB的创新突破
在算力基础设施领域,中国企业在光模块和PCB等关键部件上已具备全球竞争力,这些“隐形冠军”正支撑着全球数据中心的高速运转。
光模块:从追赶者到创新引领者
随着AI模型参数规模指数级增长,数据中心内部的数据传输需求呈爆发式增长。传统可插拔光模块正在向更高速率、更高密度、更低功耗的方向演进。中国光模块企业不仅在全球800G光模块市场中占据领先市场份额,更在1.6T及更高速率产品研发上与国际巨头同步推进。
值得关注的是,硅光技术正在改变光模块产业格局。中国企业在硅光芯片设计、硅基集成工艺和封装测试等关键环节已形成完整技术储备,部分企业已实现硅光模块的规模化量产。这种技术路径的突破,将显著降低高速光模块的成本和功耗,为超大规模AI集群提供经济可行的高速互联解决方案。
更前沿的CPO(共封装光学)技术,将光学引擎与计算芯片直接封装在一起,可大幅降低信号损耗和功耗。中国企业在CPO技术研发上已进行多年布局,与国内AI芯片企业紧密合作,共同探索下一代算力系统的架构创新。
PCB:高密度互联的基石
在AI服务器和高性能计算设备中,PCB不再是简单的连接件,而是影响系统性能、可靠性和能效的关键部件。随着AI芯片引脚数量突破上万,信号速率向112Gbps甚至224Gbps迈进,PCB需要在高多层、高密度布线、低损耗材料和高散热性能之间取得平衡。
中国PCB企业在这一高端领域进步显著。在服务器用PCB方面,国内领先企业已能批量生产20层以上、采用低损耗高速材料、满足高速信号完整性要求的高端产品。在载板领域,用于先进封装的FC-BGA基板技术不断突破,线宽线距持续微缩,为国产AI芯片的先进封装提供了本土化供应链支持。
特种PCB材料的研发也取得进展。适用于高频高速场景的改性环氧树脂、聚四氟乙烯等基板材料,以及低粗糙度铜箔等关键材料,国产化比例逐步提升,降低了高端PCB对进口材料的依赖。
算力核心:国产芯片的多元化突破
AI算力芯片是算力链的“心脏”。近年来,国产AI芯片在产品迭代、软件生态和商业应用方面均取得实质性进展,形成了多元化的产品矩阵。
训练芯片:对标国际主流水平
面对大模型训练的巨量算力需求,国产训练芯片在算力密度、内存带宽和互联技术上不断突破。新一代国产训练芯片采用先进制程工艺,集成数百亿晶体管,FP16算力达到数百TFLOPS,HBM内存带宽突破TB/s级别,全面支撑千亿参数级别大模型的分布式训练。
在芯片架构上,国产芯片不再简单模仿,而是针对Transformer等大模型主流架构进行针对性优化。通过专用矩阵计算单元、稀疏计算加速和动态精度适配等技术,显著提升大模型训练的实际效率。部分芯片在自然语言、多模态等特定模型训练任务中,已展现出与国际主流产品相当的效能。
推理芯片:场景化优势凸显
在推理芯片领域,中国企业的创新更加多元化。云端推理芯片在能效比和总体拥有成本上不断优化,支持从计算机视觉、自然语言处理到科学计算等多种工作负载。边缘AI芯片则面向智能安防、自动驾驶、工业质检等具体场景,在算力密度、功耗控制和成本优化上形成差异化优势。
值得关注的是,国产推理芯片在视频处理、推荐系统等中国优势应用场景中,通过算法与硬件的协同优化,实现了性能的显著提升。这种“场景定义计算”的创新路径,为中国AI芯片开辟了独特的发展道路。
软件生态:从可用到好用的跨越
芯片的竞争力不仅取决于硬件性能,更依赖于软件生态的完善程度。国产AI芯片在软件栈建设上已走过早期“从无到有”的阶段,正朝着“从有到优”的方向发展。
统一的编程模型和开发工具链逐步完善,支持PyTorch、TensorFlow等主流框架的模型无缝迁移。编译器优化持续深入,针对典型模型和算子的优化效果显著提升。模型库和部署工具日益丰富,降低开发者的使用门槛。这些软件层面的进步,正在缩小国产芯片与国际领先产品在易用性上的差距。
产业协同:构建高效算力服务体系
中国算力产业链的独特优势在于各环节的高效协同。从芯片设计、制造封装到服务器集成、数据中心部署,中国已形成较为完整的本土化供应链和快速响应能力。
服务器与计算设备:定制化创新
面对多样化的AI工作负载,国产服务器厂商不再提供“一刀切”的标准产品,而是针对不同场景提供定制化解决方案。面向大模型训练的高密度计算服务器,在散热设计、供电系统和结构布局上进行专门优化;面向推理场景的边缘计算设备,则在紧凑性、环境适应性和能效比上精雕细琢。
液冷技术在中国算力基础设施中快速普及。从冷板式液冷到浸没式液冷,国产解决方案在能效、可靠性和成本控制上形成特色,PUE(电能使用效率)可降至1.1以下,为大功率AI芯片的规模化部署提供了可行的散热方案。
数据中心:绿色化与智能化转型
数据中心是算力服务的物理载体。中国在超大规模数据中心建设上积累丰富经验,并在绿色化和智能化方向上不断创新。
绿色数据中心建设成效显著。通过自然冷源利用、AI智能调温、余热回收等技术,持续降低算力服务的碳足迹。在“东数西算”工程推动下,西部地区可再生能源丰富的优势与算力需求有机结合,形成绿色算力的国家布局。
数据中心运维向智能化发展。通过数字孪生、AI预测性维护和自动化运维平台,提升数据中心运营效率和可靠性,降低人工干预,为算力服务提供稳定可靠的基础环境。
应用驱动:算力赋能产业升级
中国丰富的应用场景为算力创新提供了最佳试验场。从互联网服务到传统产业转型,多样化的需求推动算力技术和服务的持续进化。
在工业制造领域,AI算力与工业知识深度融合,赋能质量控制、工艺优化和预测性维护,推动智能制造向更深层次发展。在生物医药领域,AI算力加速新药发现、蛋白质结构预测和基因分析,缩短研发周期,降低研发成本。在科学研究领域,算力成为继理论、实验之后的第三大科研范式,推动天文物理、气候变化、材料科学等基础研究的创新突破。
这种应用驱动的创新模式,形成了“真实需求-技术迭代-场景验证”的良性循环,使中国算力产业链能够快速响应市场需求,将技术突破转化为实际价值。
展望未来,中国算力链发展将呈现三大趋势:
软硬协同的深度优化:随着AI模型复杂度的提升,算力效率将更加依赖芯片架构、系统设计和算法优化的全栈协同。中国在芯片、系统和应用层面的全链条布局,为这种深度优化提供了可能。
开放生态持续繁荣:中国算力产业链的发展始终秉持开放合作的态度,积极参与国际标准制定,与国际主流技术生态保持兼容。这种开放姿态不仅有利于中国算力技术的进步,也为全球算力发展贡献了多元化的解决方案。
绿色算力成为主流:在“双碳”目标引领下,算力产业的可持续发展备受关注。从芯片级能效优化、系统级散热创新到数据中心级能源管理,绿色算力技术迎来快速发展,推动算力服务与环境保护的协调发展。
从谷歌大模型的持续突破到国内开源社区的活跃创新,AI发展正以前所未有的速度推进。这场变革的背后,是算力基础设施的全面升级和算力产业链的深度重构。中国算力链凭借在光模块、PCB、芯片等关键环节的技术积累,在产业协同和应用生态方面的独特优势,正在全球算力发展中扮演越来越关键的角色。对投资者而言,中国算力产业链的成长也将提供重要的投资逻辑和丰富的投资机会,甚至培育出未来中国科技成长的“七姐妹”(Magnificent 7)。
转载请注明:热点财经网 » 财经要闻 » AI时代的动力源—中国算力链
版权声明
本文仅代表作者观点,不代表B5编程立场。
本文系作者授权发表,未经许可,不得转载。